Difference between revisions of "Epidemics:guineapigs:model"
| Line 149: | Line 149: | ||
=== Extraction of unknown parameters === | === Extraction of unknown parameters === | ||
| + | |||
| + | Using the few experimental points in <math>V</math>, it is necessary to determine the unknown parameters <math>\alpha_1</math>, <math>\alpha_2</math>, and <math>\gamma(T,H)</math>. This is done by using the iterative algorithm described in section ''Propagation'' to generate a number of points corresponding to various reasonable parameter sets. Each of these sets will then be classified, separately for each temperature, as an approximation of parameter values for one particular humidity level <math>H</math> corresponding to the available experimental data, namely, the one that is represented by the experimental point of least distance to the point considered. After that, a search is performed for the most relevant values of <math>\alpha_1</math>, and <math>\alpha_2</math>, that cover the maximal number of experimental cases for both temperatures and with the smallest possible distances. The last step involves determination of <math>\gamma</math> values for each <math>T</math> and <math>H</math> separately. | ||
| + | |||
| + | For the simulations here we set 17 irregularly spaced checkpoints for <math>\alpha_1</math> and <math>\alpha_2</math> from 0 to 0.5, and 62 checkpoints for <math>\gamma</math> from 0.001 to 0.5. They are distributed more densely for lower parameter values. | ||
Revision as of 12:22, 21 November 2008
| Society epidemics | Guinea pigs epidemics | Virus genetic evolution |
|---|---|---|
| Data | Model | Results | ||
Contents
Model's assumptions
We have formulated a discrete stochastic model based on the probability of infection. To estimate this probability, we apply a simple generalized linear model (GLM), with 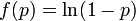 as the link function. This is a standard approach that has been successfully adopted in various related contexts for modeling influenza[1][2]. The model starts from day zero, when all non pre-infected animals are healthy. For each consecutive day, we calculate the probabilities that each individual, among those not yet infected, will be infected on that day, and then we randomly check whether any of the possible infections actually happens.
The infection history is subsequently updated, and the algorithm moves to the next day.
as the link function. This is a standard approach that has been successfully adopted in various related contexts for modeling influenza[1][2]. The model starts from day zero, when all non pre-infected animals are healthy. For each consecutive day, we calculate the probabilities that each individual, among those not yet infected, will be infected on that day, and then we randomly check whether any of the possible infections actually happens.
The infection history is subsequently updated, and the algorithm moves to the next day.
We assume the four following conditions:
1. The probability that the ith individual will be infected on a particular day (provided that it had not been infected previously) is
-
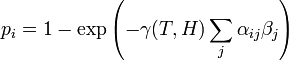
- (1)
where 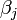 is a measure of virus concentration in the respiratory tract of the jth individual (decimal logarithm of the number of PFU in one ml of its nasal wash). The summation goes over individuals placed on the same and on adjacent shelves. Spatial coefficients
is a measure of virus concentration in the respiratory tract of the jth individual (decimal logarithm of the number of PFU in one ml of its nasal wash). The summation goes over individuals placed on the same and on adjacent shelves. Spatial coefficients 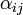 are related to the probabilities that an aerosol drop, shed by the jth animal, will get to the ith guinea pig's cage. The coefficient
are related to the probabilities that an aerosol drop, shed by the jth animal, will get to the ith guinea pig's cage. The coefficient 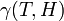 reflects the dependence of the virus transmission rate on the air temperature (T) and relative humidity (H).
reflects the dependence of the virus transmission rate on the air temperature (T) and relative humidity (H).
2. The course of influenza (virus concentration in nasal wash on the days subsequent to infection) depends only on the ambient temperature. Therefore, for each individual that became infected via air during the course of each particular experiment, the concentrations were assigned values reflecting the average case for that temperature. Table 1 shows the mean concentrations measured on particular days after infection, separately for each temperature. Functions comprising two linear pieces appear to be a reasonable guess, as shown in Figure 1.
| Day | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
Concentration, 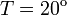 C C
|
1.52 | 4.52 | 5.63 | 6.89 | 6.06 | 3.26 | 1.88 | — | — |
Concentration, 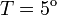 C C
|
1.91 | 4.40 | 5.72 | 7.02 | 6.01 | 4.54 | 3.52 | 1.77 | — |
| Std. deviation square | 0.40 | 0.59 | 1.26 | 0.32 | 2.38 | 1.44 | 3.18 | 2.34 | — |
 Fig.1a |
 Fig.1b |
The two piecewise linear approximations of the infection course. For 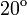 C the best fit is C the best fit is 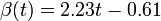 for the growing part and for the growing part and 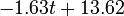 for the falling; for for the falling; for 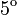 C it is C it is 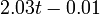 and and 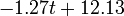 respectively. We assume respectively. We assume 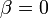 if the amount of virus is undetectable or zero if the amount of virus is undetectable or zero
| |
This may be interpreted as a two-phase infection course: first, the virus concentration grows exponentially (the scale is logarithmic), and subsequently (mostly as a result of the immune system activation) it exponentially falls. The transition between phase 1 and 2 is always sharp.
3. A detectable virus presence in the respiratory tract begins 2 days after the infection. Such an assumption is drawn from the fact that the virus was not detectable in nasal wash earlier than the third day of experiment. A lack of infections during the first day, when the virus concentrations in pre-infected individuals is supposed to be high, is of little probability. This is consistent with the major biological and clinical experience, which shows that the influenza proper begins rapidly after 2-3 days of a rather asymptomatic and non-infectious incubation period[3][4].
Accordingly, we shifted the assumed average infection course such that on the first day. The final concentration values are shown in Table 2.
4. The infection course in pre-infected individuals also consists of two linear (on a logarithmic scale) phases. Concentration values for the descending phase come from the measurement[5] (We fitted a linear function for these values. However, they were originally of a nearly linear nature.). Due to the lack of the respective experimental data, for the ascending phase we assumed the slope to be the same as for animals infected via air. The virus concentration values for those individuals are also shown in Table 2.
| Day | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| A, C
|
0.00 | 1.62 | 3.85 | 6.08 | 7.08 | 5.45 | 3.82 | 2.18 | 0.55 | 0.00 |
| A, C
|
0.00 | 2.02 | 4.05 | 6.08 | 7.06 | 5.79 | 4.52 | 3.25 | 1.98 | 0.72 |
| P, C
|
5.07 | 7.30 | 6.70 | 5.42 | 4.14 | 2.87 | 1.60 | 0.32 | 0.00 | 0.00 |
| P, C
|
4.97 | 7.00 | 8.54 | 7.32 | 6.10 | 4.87 | 3.64 | 2.42 | 1.20 | 0.00 |
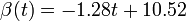 at
at 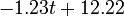 at
at Propagation of infection
Assuming values for 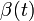 , , and
, , and 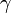 , it is possible to compute the probability of each particular healthy individual becoming infected on the first day of the experiment (Equation 1). And from the probabilities determined for days 1 to
, it is possible to compute the probability of each particular healthy individual becoming infected on the first day of the experiment (Equation 1). And from the probabilities determined for days 1 to 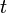 , we can calculate the value for day
, we can calculate the value for day 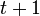 for each guinea pig in the following manner: for each sequence of days
for each guinea pig in the following manner: for each sequence of days 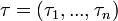 , where
, where 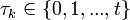 , and
, and 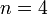 is the number of individuals to infect, let us take:
is the number of individuals to infect, let us take:
- a) the probability
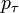 that, for each
that, for each 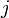 from 1 to
from 1 to 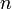 , the th individual became infected on day
, the th individual became infected on day 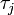 (or has not yet been infected if
(or has not yet been infected if 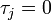 ) and
) and - b) the sum
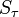 that occurs in the exponent in Equation 1 if a) is the case.
that occurs in the exponent in Equation 1 if a) is the case.
The probability 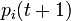 that the
that the 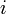 th individual will become infected on day may then be considered as the expected value of a random variable which takes values
th individual will become infected on day may then be considered as the expected value of a random variable which takes values
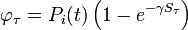
with probabilities . Hence it equals
-
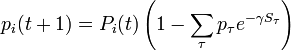 .
.
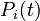 is the probability that the th individual has not been infected previously, i.e., up to day (if it has, infection cannot happen anymore).
Of course,
is the probability that the th individual has not been infected previously, i.e., up to day (if it has, infection cannot happen anymore).
Of course,
-
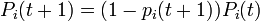 .
.
The above procedure establishes an iterative method for finding the infection probabilities on each consecutive day. The results are consistent with what was obtained from a number of Monte Carlo simulations, run with the same parameter values.
The coefficients indicate the fraction of the virus shed by the individual that contributes to infecting the individual . We assume the following:
- a)
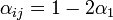 if the individual is located on the same shelf, in the adjacent column
if the individual is located on the same shelf, in the adjacent column - b)
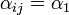 if it is located on an adjacent shelf, in the adjacent column
if it is located on an adjacent shelf, in the adjacent column - c)
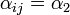 if it is located on an adjacent shelf, in the same column (so it is not pre-infected).
if it is located on an adjacent shelf, in the same column (so it is not pre-infected).
This is due to the fact that the virus particles shed by a particular animal from the pre-infected column will move mainly to the other cage located on the same shelf. However, a certain fraction of them, 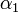 , may diffuse to each of the two adjacent shelves (or out of the system if the source shelf is at the edge). In addition, a certain fraction
, may diffuse to each of the two adjacent shelves (or out of the system if the source shelf is at the edge). In addition, a certain fraction 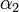 of the virus shed by individuals infected via air may also cross the shelf border and reach a neighboring animal in the same column. It seems reasonable to expect that
of the virus shed by individuals infected via air may also cross the shelf border and reach a neighboring animal in the same column. It seems reasonable to expect that 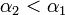 .
.
We have already assumed that the virus concentration is always the same for all pre-infected individuals. The part of that comes from them is then equal to this concentration (multiplied by 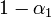 if the respective individual is located on the very top or bottom shelf).
if the respective individual is located on the very top or bottom shelf).
An infection space
The coefficients , , and must be determined experimentally. In order to do so, we introduce a 3-dimensional vector space 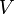 . The result of a particular experiment will be represented by a vector
. The result of a particular experiment will be represented by a vector ![v = [x,t,\sigma] \in V](/images/math/c/7/6/c76a73855d52adc4770abc9d91259998.png) . The coordinates of this vector, in a certain base, have the following meaning:
. The coordinates of this vector, in a certain base, have the following meaning:
-
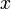 = the ratio of the individuals that were infected via air during the whole experiment to all the previously healthy individuals
= the ratio of the individuals that were infected via air during the whole experiment to all the previously healthy individuals - = the average time (number of days) elapsed before infection onset
-
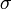 = standard deviation for the distribution of infection onset days.
= standard deviation for the distribution of infection onset days.
We define a metric tensor on as
-
![g = \left[\begin{array}{ccc} 10 & 0 & 0\\
0 & 5 & 0\\
0 & 0 & 2 \end{array}\right]](/images/math/c/3/4/c347fbbae348da13dd71bb3d547ac3bd.png) .
.
Thus, we are able to compute an abstract distance between two post-experimental states 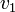 ,
, 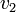 by simply taking the square root of the scalar product of
by simply taking the square root of the scalar product of 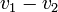 with itself:
with itself:
-
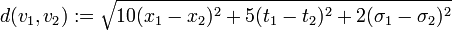 .
.
This will allow comparison of the results of different experiments and simulations quantitatively. The diagonal terms of 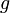 have been chosen according to the range of variety of appropriate coordinates. We have set a large coefficient (equal to 10) for the total infection rate as it is a value between 0 and 1, and differs only slightly. On the other hand, the standard deviation of infection day, , is taken with a small coefficient (equal to 2) because it may differ considerably, even for simulations performed with similar parameter values. Note that this choice, although it seems reasonable, is arbitrary. Using another distance definition, it is possible to obtain quite different results.
have been chosen according to the range of variety of appropriate coordinates. We have set a large coefficient (equal to 10) for the total infection rate as it is a value between 0 and 1, and differs only slightly. On the other hand, the standard deviation of infection day, , is taken with a small coefficient (equal to 2) because it may differ considerably, even for simulations performed with similar parameter values. Note that this choice, although it seems reasonable, is arbitrary. Using another distance definition, it is possible to obtain quite different results.
Distances between points representing the experiments of Lowen et al. (2007) are collected in Table 3.
| 20% | 35% | 50% | 65% | 80% | |
|---|---|---|---|---|---|
| 20% | — | 1.20 | 3.75 | 1.39 | x |
| 35% | x | — | 3.82 | 1.23 | x |
| 50% | X | 1.88 | — | 2.60 | x |
| 65% | x | 2.61 | 1.21 | — | x |
| 80% | x | 4.15 | 2.33 | 1.77 | — |
Extraction of unknown parameters
Using the few experimental points in , it is necessary to determine the unknown parameters , , and . This is done by using the iterative algorithm described in section Propagation to generate a number of points corresponding to various reasonable parameter sets. Each of these sets will then be classified, separately for each temperature, as an approximation of parameter values for one particular humidity level  corresponding to the available experimental data, namely, the one that is represented by the experimental point of least distance to the point considered. After that, a search is performed for the most relevant values of , and , that cover the maximal number of experimental cases for both temperatures and with the smallest possible distances. The last step involves determination of values for each
corresponding to the available experimental data, namely, the one that is represented by the experimental point of least distance to the point considered. After that, a search is performed for the most relevant values of , and , that cover the maximal number of experimental cases for both temperatures and with the smallest possible distances. The last step involves determination of values for each  and separately.
and separately.
For the simulations here we set 17 irregularly spaced checkpoints for and from 0 to 0.5, and 62 checkpoints for from 0.001 to 0.5. They are distributed more densely for lower parameter values.
References
- ↑ FERGUSON N M, Cummings D, Cauchemez S, Fraser C, Riley S, Meeyai A, Iamsirithaworn S, and Burke D, Strategies for containing an emerging influenza pandemic in Southeast Asia, Nature, 437 (2005), p209
- ↑ STEGEMAN A, Bouma A, Elbers A R W, de Jong M C M, Nodelijk G, de Klerk F, Koch G, van Boven M,Avian Influenza A Virus (H7N7) Epidemic in The Netherlands in 2003: Course of the Epidemic and Effectiveness of Control Measures, J. Inf. Dis. 190, 2004
- ↑ Carrat F, Vergu E, Ferguson N M, Lemaitre M, Cauchemez S, Leach S, Valleron A J, Time Lines of Infection and Disease in Human Influenza: A Review of Volunteer Challenge Studies, Am. J. Epid. 167(7), 2008
- ↑ Collier L, Oxford J, Human virology, Oxford University Press, 1993
- ↑ Lowen A C, Mubareka S, Steel J, Palese P, Influenza Virus Transmission Is Dependent on Relative Humidity and Temperature, PLoS Pathogens 3(10), 2007, p151